¹M.tech Pawan Sisodia, Department of Computer Science & Engineering Suresh Gyan Vihar University, Jaipur
²Assistant Professor Raminder Kaur, CSE/IT Department Suresh Gyan vihar University, Jaipur
Abstract — The Credit Card Fraud detection is a challenging task for researchers as fraudsters are innovative, quick moving individuals. Credit Card fraud detection system is challenging as the dataset provided for credit card fraud detection is very imbalanced, as the quantity of false exchanges is a lot littler than the real ones. Thus, many of fraud detection models got failed due to these data sets. This aim of this research work is to enhance performance of the minority of credit card fraud on the dataset available. So, K-means clustering, logistic regression, random forest and XGBoost models are performed. This research work incorporates the Credit Card Fraud Detection models to study the transactions that end with some frauds. This paper is then used to distinguish whether payment transactions are fraud or not. This research work is to identify totally the false transactions while avoiding the incorrect fraud classifications. Different algorithms are implemented in this paper. Python Machine Learning libraries are used to perform those algorithms. The models studied in this research work are K-Nearest Neighbour, logistic regression, random forest model, XGBoost model. XGBoost is showing more accuracy then other models. Out of these algorithms, XGBoost model is preferable over Random Forest model and Logistic regression model.
Keywords— Credit Card Fraud Detection, K-Means Clustering, Logistic Regression, Random Forest, XGBoost Model
- INTRODUCTION
The Credit Card Fraud detection is a challenging task for researchers as fraudsters are innovative, quick moving individuals. With credit card transactions, there are two types of frauds:
- Traditional Types of Fraud
- Modern Types of Fraud
The principle kind of credit card extortion is illegal use of Lost and Stolen Cards. Creating Fake and Doctored Cards is in the cutting edge procedures, wherein the data is hung on either the attractive strip on the rear of the credit card, or the data set aside on the savvy chip is copied beginning with one card then onto the following. Phishing websites are changing into a standard method of blackmail with a talented hacking limit. These kinds of the pages are proposed to get individuals to give their credit-cards details effectively without recognizing they have been frauded. Triangulation is comparably another method. Triangulation is the point at which a seller offers a thing at an incredibly unassuming cost through a site. At the point when a client attempt to submit the request of the item, the transporter urges to the customers or clients who are in snare, to pay by methods for email if the item is gotten by him. The seller uses a misleading card details for buying the item from a site and sends the thing to the buyer, who at that point send the trader their credit card details by means of email. The trader continues working along these lines utilizing the credit-card numbers given by buyers for buying; showing up for a brief time frame to be the individual closes the web page and begins another one.
The misrepresentation of credit cards may be performed in two ways, either offline or online (fraud). Offline fraud is possible if the client faces the venue or by call centre has a physical card stolen. Before it is falsely used, the card issuing banks or organisations can jolt it. Online error is displayed via telephone shopping, web pages or if cardholders are not in attendance. The loss of individual data straightforwardly adds to developing misrepresentation misfortunes for banks and merchants. It is important to collect key details for reasons of breaches to avoid losses from financial service organization. Planning of this study is to help fraud supervisory groups figure out where holes exist in the security issues in this industry.
Figure: 1.1 Increase problems due to breaches
Much like payment card, ledger accreditations are sold by fraudsters at a fast pace. This has caused it progressively workable for programmers with any dimension of preparing to submit account takeover misrepresentation. The accessibility of budgetary accreditations over the dark web has additionally helped fraudsters to submit account to take over on a bigger scale. While fraudsters keep on benefiting from vulnerabilities that exist over the installments, retail and financial industries. These problems are going to continue to be exacerbated at a rapid pace.
In the recent years, with the frequent information rupture, fraud is top of mind with many people. Lawbreakers are progressively utilizing tricks to fool individuals into uncovering their own subtleties or parting with their money. Open attention is crucial if the fraudsters are to be dealt with. Cross-payment card, remote banking and control related monetary misfortune totalled £755 million each 2015, up 26% from 2014. Card not present payments (CNP), i.e. web page payments or online payments (73 percent), point of sale (POS) (19 percent), and automated teller transactions are currently responsible to 73 percent of card fraud (ATMs). In 2018, Card-Not-Present (CNP)-frauds are emerging because of non-presence of customer in online transactions. In U.S, there was highest sale on ecommerce businesses as 77% of traders are selling products online but percentage of CNP fraud also increases as shown in figure.
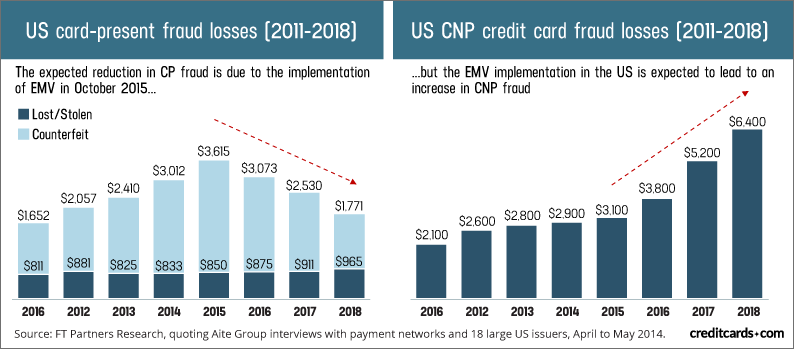
Figure: 1.2 Credit Card Fraud Losses
II. Existing techniques
Linda0Delamaire, Hussein0Abdou and John0Pointon (2009) Fraud in the credit card industry is one of the real good problems. The main focus is to recognise the various kinds of extorsion by credit cards directly off the bat and, in addition, to examine electives used in deception. The sub-point is to display, take a gander at and analyze starting late conveyed revelations in card fraud detection.
V.Dheepa,0and0Dr.R.Dhanapal (2009): The incredible increment in credit card transactions, charge card coercion has ended up being logically wild starting late. In Modern day the coercion is one of the genuine purposes behind exceptional money related setbacks, not only for brokers, solitary clients are in like manner impacted. Three procedures to recognize coercion were presented. In the first place, the collection model was used to organise legal and falsified exchanges using the collection of data in parameter fields.
John Akhilomen (2013): Since the development of the web, various little and colossal associations have moved their associations to the web to offer organizations to customers around the globe. The misrepresentation of digital charging cards or no coercion presented by cards is continually uncontrolled over time because0that the Mastercard is used to request portions on the Web from such associations. Therefore, the need to make electronic portions for items and adventures provided on the web is an example of controlled exchange for Credit0card owners.
- R. Seeja and Masoumeh Zareapoor (2014): With the appearance of communications systems, web-based business just as online payment transactions are expanding step by step. Nearby this budgetary cheat related with these trades are similarly elevating which that causes billions of dollars losses reliably universally. Among the different monetary fakes, Visa extortion is the most old, normal, and hazardous one in view of its broad use because of the solace7it offers to the customer.
- Sivakumar0and0 Dr. R. Balasubramanian (2015): Technological advancements made the things where we see money. ‘Cash on delivery or pay after buying, acknowledge today and pay when able’ in perspective on this the Banks displayed Visas. Every shop in every country provides cashless shopping. The progress made in the development of electronic exchanges, the use of charging cards, and it has become the standard strategy7 for the portion of web and unit purchases.
Ibtissam0Benchaji, Samira0and Bouabid0El0Ouahidi (2018) With the creating usage of credit card transactions, money related misrepresentation violations have furthermore been certainly extended provoking the loss of tremendous holes in the record business. Having a profitable blackmail disclosure strategy has transformed into a requirement for all banks in order to constrain such mishaps. Honestly, charge card deception revelation structure incorporates an essential test: The Credit card blackmail educational files are significantly imbalanced since the amount of false exchanges is much more diminutive than the genuine ones.
Yashvi0Jain,0Namrata Tiwari,0Shripriya Dubey and0Sarika Jain (2019) Fraud is any malignant action intended to make the other party budgetary unhappiness. The extortion associated with advanced cash or plastic cash is also rising in creating nations. Buyers and banks 0 billion dollars are charged for cheats caused by credit cards all inclusive. Indeed, fraudsters persistently seek new ways and traps to make misrepresentations even after various components stop extortion. Consequently, so as to stop these fakes we need a ground-breaking extortion identification framework which recognizes7the misrepresentation as well as7identifies it before it happens and in an exact7way.
In 2015, J. Esmaily and R. Moradinez had in their paper projected a hybrid of pretend neural system and decision tree. In their model, they utilized a two-stage approach. In 1st stage the characterization consequences of decision tree and Multilayer recognition were utilized to provide another dataset that in second stage is feed into Multilayer observation to at long last organize the knowledge. This model guarantees unwavering quality by giving low false recognition rate. Siddhartha Bhattacharyya and four others in their paper in 2011 completed purpose by point similar investigation of Support vector machine and irregular woods aboard calculated relapse.
In 2015, Tanmay Kumar and Suvasini Panigrahi in their paper projected a mix thanks to agitate credit card extortion recognition utilizing downy bunching and neural system. It utilizes 2 stages. In stage one, they utilized a c-implies grouping calculation to provide a suspicious score of the exchange associate degree in next stage if an exchange is suspicious it’s feed into neural system to make your mind up if it had been extraordinarily false or not.
III. METHODOLOGY
3.1 Dataset
The data set used in the proposed work is provided by Kaggle. There are overall 30 features. But 28 out of them are renamed as V1 through V28. All are numeric values. The remaining three features are the time, transaction amount status of the transaction, it was fraudulent or not. The exact details of the features are hidden for confidentiality. The, Class, response variable is 1 for fraudulent transaction and 0 for safe transactions. Supervised approach is used in this work. There are no missing values in the data set.
Requesting for Transaction Info of dataset:
- # requesting for transaction info
- info
The above requested command over the credit card dataset will return the overall transaction information as displayed in figure below:
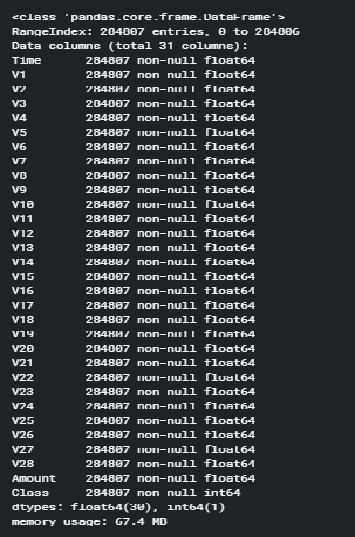
Figure: 3.1 Transaction Info dataset
3.2 Train and Test Split
It is important to split data into response variables for implementation of any model.
- X = transactions.drop(labels=’Class’, axis=1) #Features
- y = transactions.loc[:, ‘Class’] #Response
- deltransactions # delete the original data
Test size should be 20%. There are very less fraudulent transactions, so it is important to split.
- frommodel_selection importtrain_test_split
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=2, random_state=1, stratify=y)
- #delete unwanted, prevent memory leak
- delX, y
- #get the shape
- shape
3.3 Exploratory Data Analysis
EDA is performed only on the training session and unknown from the test set. The time and quantity of EDA transactions are not anonymised. There are 284,807 transactions in the data set. The average value of all transactions is $88.35, and in this data set the biggest transaction is $25,691.16. However, the monetary value of all transactions is heavily redefined, as you can currently guess, on the basis of their average and maximum. The overwhelming majority of transactions are relatively small and only a small fraction is even close to the maximum.
3.4 TIME vs AMOUNT
A common histogram can be drawn up using hexagonal containers to find the relation between the transaction amounts and the time of the day. Every transaction time is converted to the hour of the day in this plot.
- # plot the graph
- jointplot(X_train[‘Time’]).apply(lambdax: x % 24), X_train[‘Amount’], kind=’hex’, stat_func=None, size=12, xlim(0,24), ylim(-7.5,14)).set_axis_labels(‘Time of Day (hr)’,’Transformed Amount’)
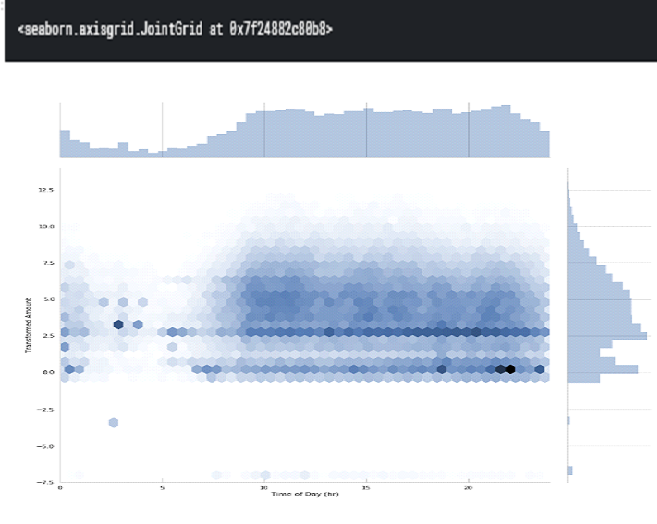
Figure: 3.2 Time vs Transactions
TheTtransactionTamountsTappearTtoTbeTsimilarlyTdistrib utedTthroughoutTtheTdaytime hours.
However,TinTtheTearliestThoursTofTtheTday,TaroundT5 to 7TAM, amounts around 2.5TareTthe most common (recall this is a Box-Cox transformed value).
3.5 MUTUAL INFORMATION BETWEEN FRAUD AND THE PREDICTORS
Mutual information is a non-parametric method for estimating mutual dependency between two variables. Currently, low values do not indicate dependency; higher values indicate greater dependence. According to the sklearn User Guide, “mutual information methods may record any statistically dependent method but, since they are nonparametric, require more samples for an exact estimate. We use mutual info class if (unlike mutual info regression8for a continuous8objective) because of the discrete objective variable.
- fromfeature_selection importmutual_info_classif
- mutual_infos = pd.Series(data=mutual_info_classif(X_train, y_train, discreate_feature=False), random_state=1), index=X_train.columns)
The calculated8mutual8information of each variable8with Class, in descending8order:
- sort_values(ascending=False)
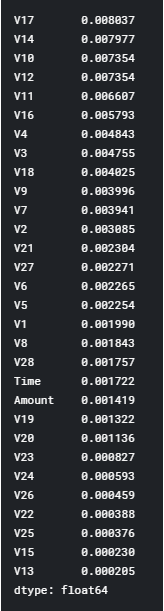
Figure: 3.3 Mutual Information Values
V17, 8V14, 8V10, 8V12, and 8V11 are in decreasing order and are five variables which are highly correlated with Class.
- RESULT
- Algorithms Implemented
To create machine models for prediction of fraudulent transactions. We implement the following models.
- K8Nearest8Neighbors (KNN)
- Logistic8regression
- Support8vector8classifier
- Random forest
- XGBoost
In the classification8setting, the KNN8algorithm is forming a majority vote between the K8most similar instances8to a given unseen8observation. Similarity is defined according to a8distance metric between two8data points x and x0 .
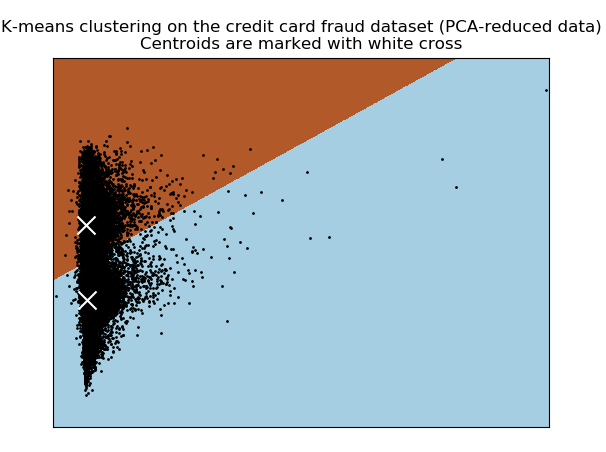
Figure: 4.1 K-Means8Clustering
4.2 Logistic Regression and Support Vector Classifier
Logistic regression introduced by David Cox,1958 is a model in which the response variable Y is categorical. It gives the presence of a predictor8increases (or decreases) the probability of a given outcome by a specific percentage.
SVM introduced by Vapnik,1995 was to solve the classification and regression problems. It is used to derive an optimal hyper0plane that maximizes the margin between two0classes.
With SGD training, the class SGD Classifier implements several linear classifiers, making learning on large datasets much quicker. We will use the model as a pipeline for machine learning, including a standard scalar for data standardization (rescaling each variable to zero mean and unit variance).
- frompipeline importPipeline
- frompreprocessing importStandardScaler
- fromlinear_model importSGDClassifier
- pipeline_sgd = Pipeline([
- (‘scaler’, StandardScaler(copy=False)),
- (‘model’, SGDClassifier(max_iter=1000, tol=1e-3, random_state=1, warm_start=True))
- ])
Search Grid through multiple choices of hyper parameters. The search uses 5 times stratified folded cross validation. The linear classifier type is selected by the loss parameter hyper. We have set loss = ‘hinge’ for a linear SVC. We have set loss = ‘log’ for logical regression. Sets the hyper grids, an SVC Grid and a Logistic Regression grid to search through SVC:
- param_grid_sgd = [{
- ‘model__loss’: [‘log’],
- ‘model__penalty’: [’11’, ’12’],
- ‘model__alpha’: np.logspace(start=3, stop=3, num=20)
- },{
- ‘model__loss’: [‘hinge’],
- ‘model__alpha’: np.logspace(start=3, stop=3, num=20),
- ‘model__class_weight’: [None, ‘balanced’]
- }]
Grid search, conducted by GridSearchCV0, uses StratifiedKFold0 5 folds for the split between train and validation. As our score metric, we will use 0matthews corrcoef (Matthews correlation factor, MCC).
- frommodel_selection importGridSearchCV
- frommetrics importmake_scorer, matthews_corrcoef
- MCC_scorer = make_scorer(matthews_corrcoef)
- grid_sgd = GridSearchCV(estimator=pipeline_sgd, param_grid=param_grid_sgd,
- scoring=MCC_scorer, n_jobs=1, pre_dispatch=’2*n_jobs’, cv=5, verbose=1,
- return_train_score=False)
Perform the grid search:
- importwarnings
- with warnings.catch_warnings(): #Suppress warnings from the matthews_corrcoef fn
- simplefilter(“ignore”)
grid_sgd.fit(X_train, y_train)
Mean cross-validated MCC score of the best estimator found:
- # calculate the best score
- best_score_
Output : 0.8075666039570759
We have 492 fraud data points and 284315 non-fraudulent data points.
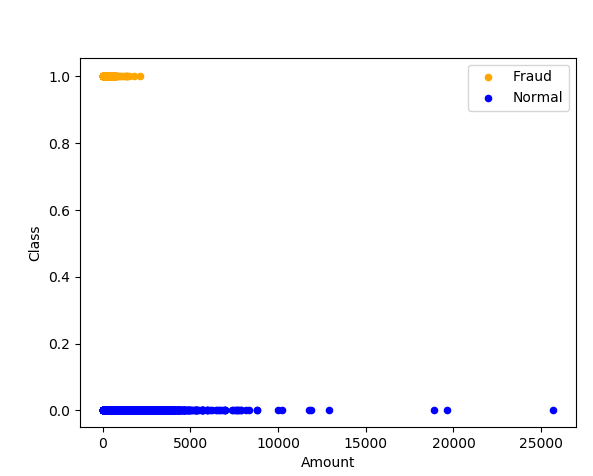
Figure: 4.2 Types of Transactions(1)
Figure: 4.3 Types of Transactions(2)
Figure: 4.4 Types of Transactions(3)
and the generated output is:
FNR is 0.40425531914893614
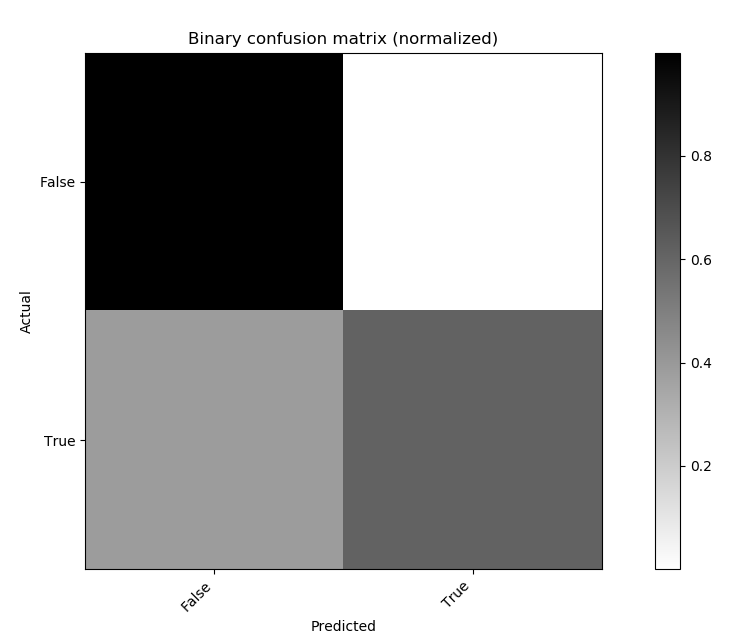
Figure: 4.5 Binary Confusion Matrix for K-Means Model
4.3 Random Forest
The random0forest0algorithm by0L. Breiman ,2001, has0been successful as a general-purpose0classification and0regression method. This approach uses several randomized decision trees0and0aggregates their predictions0by averaging, has shown0excellent performance0in the setting having greater the number of observations then the number of variables.
It is applied to large-scale problems and is easily adapted to0various ad-hoc0learning tasks, 0and returns0measures of variable importance.0The random forest model is implemented in0RandomForestClassifier.
Output: 0.8567203839327452
As compared to SVC, random forest performed very well.
CONCLUSION
The proposed methodology adopted is proficient and viable. The random forest model and XGBoost are options to precisely recognize fraudulent credit card transactions. We found that the five factors V17, V14, V10, V12, and V11 are most associated with fraud. The fraud transactions can look fundamentally the same as standard exchanges; it is hard to place them into a different gathering dependent on highlights alone. The K-implies grouping model delivered a low precision of 54.27%. Subsequently, K-means would not be the favored model for this data set, as it didn’t effectively anticipate cheats and it likewise created a great deal of false positives. The strategic relapse gave us the best outcomes. The logistic regression gave us an extraordinary precision rate of 99.88%, with 0.079% of the approval set being false negatives (or 0.49% of the number of frauds). It has been appeared even a logistic regression model can accomplish great review, while a significantly more complex Random Forest model enhances strategic relapse as far as AUC. Be that as it may, XGBoost model enhances the two models. The Random forest model can be improved further by manipulating the hyper parameters.
FUTURE SCOPE
Issues of Fraud detection are mind-boggling require a considerable measure before the implementation of AI algorithms. The utilization of AI algorithms and business analytics ensures that the cash of the customers will be safe and not effectively messed with. In future work, Random forest mode would be improved for detecting fraudulent transactions.
ACKNOWLEDGEMENT
The author expresses deep sense of gratitude towards the Suresh Gyan Vihar University Jaipur for allowing & supporting this work. The author also expresses gratitude towards the Suresh Gyan Vihar University Group Jaipur, for their timely help & support.
REFERENCES
- Linda Delamaire, Hussein Abdou and John Pointon(2009) ”Credit card fraud and detection techniques: a review” Banks and Bank Systems, Volume 4, Issue 2, 2009
- Dheepa, and Dr. R.Dhanapal (2009) “Analysis of Credit Card Fraud Detection Methods” International Journal of Recent Trends in Engineering, Vol 2, No. 3, November 2009
- John Akhilomen(2013) “Data Mining Application for Cyber Credit-Card Fraud Detection System” Advances in Data Mining. Applications and Theoretical Aspects pp 218-228
- Excell D. Bayesian inference—the future of online fraud protection. Computer Fraud and Security. 2012;2012(2):8–11.
- Lu Q, Ju C. Research on credit card fraud detection model based on class weighted support vector machine. Journal of Convergence Information Technology. 2011;6(1):62–68.
- Juszczak P, Adams NM, Hand DJ, Whitrow C, Weston DJ. Off-the-peg and bespoke classifiers for fraud detection. Computational Statistics and Data Analysis. 2008;52(9):4521–4532.
- Holmes G, Donkin A, Witten IH. Weka: a machine learning workbench. Proceedings of the 2nd Australia and New Zealand Conference on Intelligent Information Systems; 1994.
- Witten IH, Frank E, Hall MA. Data Mining: Practical Machine Learning Tools and Techniques. 3rd edition. San Francisco, Calif, USA: Morgan Kaufmann; 2011.
- Bhattacharyya S, Jha S, Tharakunnel K, Westland JC. Data mining for credit card fraud: a comparative study. Decision Support Systems. 2011;50(3):602–613.
- Blunt G, Hand DJ. London, UK: Department of Mathematics, Imperial College; 2000. The UK credit card market.
- Bolton RJ, Hand DJ. Unsupervised profiling methods for fraud detection. Proceedings of the Conference on Credit Scoring and Credit Control; 2001; Edinburgh, UK.
- Bolton RJ, Hand DJ. Statistical fraud detection: a review. Statistical Science. 2002;17(3):235–255.
- Ngai EWT, Hu Y, Wong YH, Chen Y, Sun X. The application of data mining techniques in financial fraud detection: a classification framework and an academic review of literature. Decision Support Systems. 2011;50(3):559–569.
- Zareapoor M, Seeja KR, Alam AM. Analyzing credit card: fraud detection techniques based on certain design criteria. International Journal of Computer Application. 2012;52(3):35–42.
- Aleskerov E, Freisleben B. CARD WATCH: a neural network-based database mining system for credit card fraud detection. Proceedings of the Computational Intelligence for Financial Engineering; 1997; pp. 220–226.
- Ghosh S, Reilly DL. Credit card fraud detection with a neural network. Proceedings of the 27th Hawaii International Conference on System Sciences; January 1994; Wailea, Hawaii, USA. pp. 621–630.
- Francisca NO. Data mining application in credit card fraud detection system. Journal of Engineering Science and Technology. 2011;6(3):311–322.
- Quah JTS, Sriganesh M. Real-time credit card fraud detection using computational intelligence. Expert Systems with Applications. 2008;35(4):1721–1732.
- Zaslavsky V, Strizhak A. Credit card fraud detection using self-organizing maps. Information & Security. 2006;18:48–63.
- Duman E, Ozcelik MH. Detecting credit card fraud by genetic algorithm and scatter search. Expert Systems with Applications. 2011;38(10):13057–13063.
- Maes S, Tuyls K, Vanschoenwinkel B, Manderick B. Credit card fraud detection using Bayesian and neural networks. Proceedings of the 1st International NAISO Congress on Neuro Fuzzy Technologies; 1993; pp. 261–270.
- Srivastava A, Kundu A, Sural S, Majumdar AK. Credit card fraud detection using hidden Markov model. IEEE Transactions on Dependable and Secure Computing. 2008;5(1):37–48.
- Chan PK, Fan W, Prodromidis AL, Stolfo SJ. Distributed data mining in credit card fraud detection. IEEE Intelligent Systems and Their Applications. 1999;14(6):67–74.]
- Seyedhossein L, Hashemi MR. Mining information from credit card time series for timelier fraud detection. Proceeding of the 5th International Symposium on Telecommunications (IST ’10); December 2010; Tehran, Iran. pp. 619–624.
- Sánchez D, Vila MA, Cerda L, Serrano JM. Association rules applied to credit card fraud detection. Expert Systems with Applications. 2009;36(2):3630–3640.
- Syeda M, Zhang Y-Q, Pan Y. Parallel granular neural networks for fast credit card fraud detection. Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE ’02); May 2002; Honolulu, Hawaii, USA. pp. 572–57.
- Wong N, Ray P, Stephens G, Lewis L. Artificial immune systems for the detection of credit card fraud. Information Systems. 2012;22(1):53–76.
- Panigrahi S, Kundu A, Sural S, Majumdar AK. Credit card fraud detection: a fusion approach using Dempster-Shafer theory and Bayesian learning. Information Fusion. 2009;10(4):354–363.