Vaibhav Bhardwaj
M.Tech Scholar, Department of CEIT, Suresh Gyan Vihar University, Jaipur
vaibhav.bhardwaj@mygyanvihar.com
Manish Sharma
Associate Professor, Department of CEIT, Suresh Gyan Vihar University, Jaipur
manish.sharma@mygyanvihar.com
Abstract: Speaker recognition is a challenging task in the field of science and technology. There are various methods for recognition of a speaker. Some of the researchers were used the signal processing technique using embedded systems and some are using programming algorithms to accomplish this task. Digital signal processing is also an efficient tool for this task. Here we are using an artificial intelligent (AI) based technique to complete this task. Here we are trying to differentiate the sound of APJ Abdul Kalam and the Donald Trumph president of America. Herewe are using K-nearest neighbor (KNN) algorithm which is a powerful supervised learning tool. We have extract the five parameters of sound and these are ‘chroma_stft’, ‘chroma_cqt’, ‘zero_crossing_rate’ and ‘mfcc’.
Keywords: KNN, Chroma, Zero crossing, MFCC, Supervised learning.
- INTRODUCTION
Speaker recognition is related to speaker identification and speaker verification problems. Speaker identification is a taskto identify the provided speech sample (utterance) as belonging to one speaker from the set of known speakers (1:Nmatch). Comparison between people who speak their own words for accepting or rejecting the ratio (1: 1). The gift of prayer, can be a talk, or that may be. You do not know that those who take the language itself and encoding 1, between someone who speaks a word against the tongue, is not the same or any statement from the signification of , says whosoever. In cases where the right is not very well known. With the development of the Emerald Bio and one of the most important aspects of the doctrine of the evidence system, this is more and more information. Many speakers download features like Mel Frequency cepstral coefficients (MFCC) [1] and the collection of background data created by imitation Universal Background Model (UBM) and Gaussian Mixed Model (GMM)) [ 2, 3] describes the meaning of human language. Linear discriminate analysis (LDA) is often used for feature variance between the most and least feature vectors. Increasing the neural network (DNN) feature is the only Bottle Neck Features (BNF) [4] With DNN large part of the training being divided into the business and going to step into the third, as a passenger. This feature is used as a vector standard for the description of all speakers. All users are the same developer.Modern design often uses a combination of features such as the MFCC feature changed from the source unit and the BNFStill LDA. The results of the room model of the demise or the equivalent of a heavyweight contest details.Consult with security hardware [5]Capacity to limit the speed of uiriumlet the drawing not be used type. The truth is simple to use it also allows multiple algorithms to slow post and when he prayed and the signTemplate. Automatic speaker recognition (ASR)Model was introduced in recent years to work in a binary [6, 7],However, two unique MFCC The function of some of the features that are appropriate for a feeling;Industry.
Here we are trying to differentiate the sound of APJ Abdul Kalam sir and the Donald Trumph president of America. Here we are using K-nearest neighbor (KNN) algorithm which is a powerful supervised learning tool. We have extract the five parameters of sound and these are ‘chroma_stft’, ‘chroma_cqt’, ‘zero_crossing_rate’ and ‘mfcc’.
II. SPEAKER INFORMATION
In this paper we have use the python programming to create the model and run the algorithms. We have chosen two speakers first is Dr. APJ Abdul Kalam and second is Mr. Donald Trumph. We have chosen these two speakers because there is a lot of variation in both of these sounds. If we take the both samples of Indian citizen then model can be create some confusion in decision making. The idea is to identify the speakers even if they speak the same password. The following figure shows the system’s architecture.
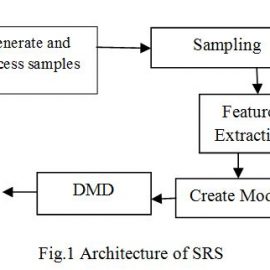
- Generation and Process on samples:
We have downloaded a speech of both Dr. Kalam and Trumph. After removing the noise from the speech we had a sample size of 56 min. We chunk 1099 samples from these speeches of 55 min. the sampling rate of the signal was 11025 Hz.
- Sampling
Computer is a digital device. It works only on the discrete samples. Here is sampled the signal with the rate of 11025 Hz.
- Feature extraction
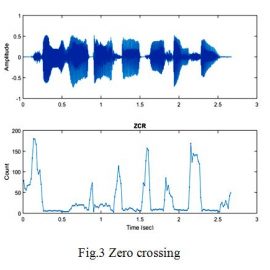
Zero crossing: Zero crossing represents that the speakers audio signal for each sample, how many times cutting the zero line.
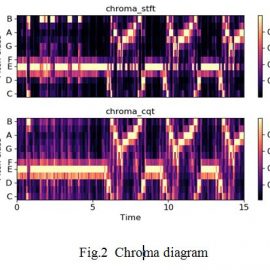
Chroma STFT:We use “Shepard Tones”, which consist of a mixture of all sinusoids carrying a particular chroma, for re synthesis. Compute a chromagram from a waveform or power spectrogram
Chroma CQT:Constant-Q chromagram. Chroma stft and cqt are shown in Fig. 2.
Here we are extracting the five features
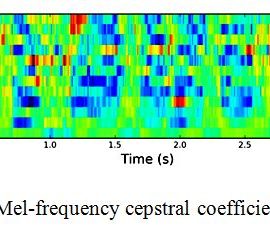
MFCC: Mel-frequency cepstral coefficients is a short term power spectrum. Instead of taking the power spectrum density we use the mfcc of the audio signal.
III. EXPERIMENTAL SETUP : Experimental testing requires dataset with speakers and evaluation criteria.
- Dataset
Dataset having the following features.
- 5 utterances per speaker
- 1099 samples
- re-sampled to 11025Hz and 16 bits.
- hamming window and FFT size is 512
- Training samples: 70%
- Testing samples: 30%
- signals are sampled at 8 kHz
- K = 3
For speaker identification testing, is speaking the same language can be said to have been offered only two different things in the crowd. Other Handbook 5 [9] The set of “experiments” were removed from the neon of the two tubes and lenses, talk 65.5 conversations with 1099 volumes of volumes. Lost files are selected by EER (at least parity error) and are considered as failing fashions. In order to check the lost data that represents them, and hears 11025Hz 16 items at the bottom line.
In our body, because the voice recognition feature downloads. The visual field algorithm is applied to the signal Put the value of the power fast vector. Livy, we use the lack of cranes and FFT windows size is 512. KNN algorithm for order at the vectors of season 257. 2 speakers appears. All orators are unaware to repeat experiments in writing 90. 45 votes in 45 exams used in our study. In all our experiments Signals on 8kHz. It is our goal to know the spoken word sounds like the sound.
IV. RESULTS AND DISCUSSION
Table one is showing the sample data set of extracted features.
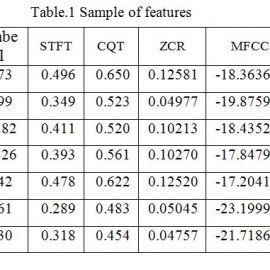
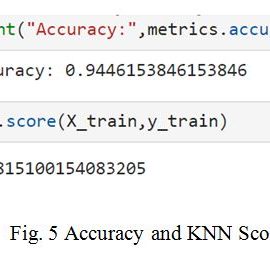

The model is trained by KNN algorithm and taking the 3 nearest neighbor. The accuracy of the system is 94% and the value of K score is 98. The system is providing the output result in probabilistic manner. There are two classes i.e. 0,0 and 0,1. It showing that if class [0,0] probability is greater than 0.7 then the result go in the favour of Dr. kalam and other wise it will choose the Trumph.
V. Conclusion
Speaker recognition is a challenging task in the field of science and technology. There are various methods for recognition of a speaker. Some of the researchers were used the signal processing technique using embedded systems and some are using programming algorithms to accomplish this task. Digital signal processing is also an efficient tool for this task. Here we are using an artificial intelligent (AI) based technique to complete this task. Here we are trying to differentiate the sound of APJ Abdul Kalam sir and the Donald Trumph president of America. Here we are using K-nearest neighbor (KNN) algorithm which is a powerful supervised learning tool.The model is trained by KNN algorithm and taking the 3 nearest neighbor. The accuracy of the system is 94% and the value of K score is 98. This showing the good estimation of detected signal.
References
[1] N. Dehak, Z. Karam, D. Reynolds, R. Dehak, W. Campbell, and J.Glass, “A Channel-Blind System for Speaker Verification”, Proc.ICASSP, pp. 4536-4539, Prague, Czech Republic, May 2011.
[2] N. Dehak, P. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet, “Front-End Factor Analysis for Speaker Verification”, IEEE Transactions onAudio, Speech, and Language Processing, Vol. 19, No. 4, pp. 788-798,May 2011.
[3] R. Togneri and D. Pullella, “An Overview of Speaker Identification:Accuracy and Robustness Issues”, In: IEEE Circuits And SystemsMagazine, Vol. 11, No. 2 , pp. 23-61, ISSN : 1531-636X, 2011.
[4] D. A. Reynolds, “A Gaussian Mixture Modeling Approach to TextIndependent Speaker Identification”, PhD Thesis. Georgia Institute ofTechnology, August 1992.
[5] T. Kinnunen and H. Li, “An overview of text-independent speakerrecognition: From features to supervectors”, Speech Communication52(1): 12-40, 2010.
[6] D. A. Reynolds, “Robust Text-Independent Speaker Identification UsingGaussian Mixture SpeakerModel”, IEEE Transactions on Speech andAudio Processing. vol. 3, n. 1, pp. 72-83, January, 1995.
[7] D. A. Reynolds, T. F. Quatieri, and R. B. Dunn, “Speaker verificationusing adapted Gaussian mixture models”, Digital Signal Process., vol.10, no. 1–3, pp. 19–41, 2000.
[8] S. Young, D. Kershaw, J. Odell, D. Ollason, V. Valtchev, and P.Woodland, “Hidden Markov model toolkit (htk) version 3.4 user’sguide”, 2002.
[9] D. A. Reynolds, “Speaker identification and verification using Gaussianmixture speaker models,” Speech Commun., vol. 17, no. 1–2, pp.91–108, 1995.
[10] W. Campbell, D. Sturim, and D. Reynolds, “Support vector machinesusing GMM supervectors for speaker verification,” IEEE SignalProcess. Lett., vol. 13, no. 5, pp. 308–311, 2006.
[11] D. Reynolds, “Experimental evaluation of features for robust speakeridentifi cation,” IEEE Trans. Speech Audio Process., vol. 2, no. 4, pp.639–643, 1994.
[12] Garofolo, J. S., Lamel, L. F., Fisher, W. M., Fiscus, J.G., Pallett, D. S.,and Dahlgren, N. L., “DARPA TIMIT Acoustic Phonetic ContinuousSpeech Corpus CDROM, “NIST, 1993.
[13] A. Martin, G. Doddington, T. Kamm, M. Ordowski, and M. Przybocki,“The DET Curve in Assessment of Detection Task Performance”, inEUROSPEECH, vol. 4, pp. 1895–1898, 1997.