pp 26-28
Subhash Chand Samota1, Gaurav Kumar Sharma2
M.Tech scholar, SGVU, Jaipur
samota8@gmail.com
Associate Professor, SGVU, Jaipur
gauravkr.sharma@mygyanvihar.com
Abstract: Here in this paper we are reviewing the last four years work in the field of speech signal processing. We have reviewed the four latest papers of speech signal processing and all these papers published from 2017 to 2018. These papers are published in IEEE journals and conference proceeding. So the complete review process is based on the recent research in speech signal processing from last three years.
Keywords: Speech Signal Processing, Fast Fourier Transform, Framing, Discrete Cosine Transform
I. INTRODUCTION
Speech signal processing is an active research area in the field of digital signal processing. Speech signal processing was come into the picture in 70’s. Some of the important aspects of digital speech processing are high quality coding (perceptual coding) of speech and audio, speech recognition, enhancement and modification of speech and audio, text-to-speech synthesis, speech-to-text synthesis etc. Here in this paper we are reviewing the last four years work in the field of speech signal processing. We have reviewed the four papers of speech signal processing and all these papers published from 2017 to 2018. Three papers are published in 2018and one papers was published in 2017. These papers are published in IEEE journals and conference proceeding. So the complete review process is based on the recent research in speech signal processing from last three years.
II. REVIEW OF PAPERS
Review.1:
Michał Raczyński et-al, 2018, describe an algorithm for recognize the sound from previously created constant words. They use the MATLAB to perform this task. First they pass the signal through the filter. They record the signal by matlab music card for 1sec. then convert the analog signal into digital signal with sampling frequency 8 khz. Obtained signal is fitted to constant length of frame equal 6000 samples, using resembling method. They use the PLA technique to recognize the world. Complete set of operational diagram is shown in Fig.1
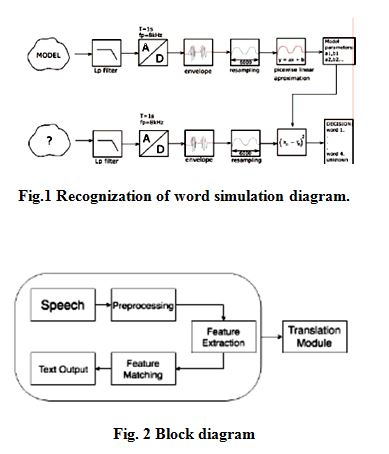
The performance criterion was mean square error. The testing result of the above experiment was 80% accurate.
Review. 2:
Hariz Zakka Muhammad et-al, 2018 were designed a speech recognization model wher speech was interpreting into indonesian language. They use the feature extraction method Mel Frequency Cepstral Coefficients (MFCC) and for this purpose they were used the “Markov Model” For this purpose they use the following block diagram process. The complete process was divided into two parts first training and second is testing process. The execution method is shown in Fig3.
According to Fig.3 first they create the data base of audio sound. Then do the audio signal processing to extract the features from the original signals.

They apply the k-means clustering algorithm on the featured data. It’s an unsupervised algorithm. The recognition process is done by finding the likelihood value of all λ models. The MFCC process has following steps:
- Pre-emphasis
- Framing
- Windowing
- Fast Fourier Transform (FFT)
- Filter Banks
- Discrete Cosine Transform (DCT)
Finally they apply the hidden markov model for optimization. They found the 70 percent average accuracy.
Review. 3:
Prashant Upadhyaya et-al, Measure the performance of kaldi speech recognization tool using Speaker Adaption Technique (SAT).They used the machine learning technique for the detection purpose. Feature was acoustic Balance according to MFCC 1000 and PLP symbols. Hindu proposal from AMUAV body. Acoustic training models are using the hidden Markov model and the Gaussian modeling model. (NHM-GMM) and limited weight conversion State Transducer (WFST) improved by 6.93%.

Speech recognition model in Kaladi is based on final state the converter with the main library has been written in C ++ language support Flexible code is easy to understand actively. Kaladi Apache v2.0 supported by license, which are appropriate large community user base business. They achieve the 7% improvement in recognization. Architecture of speech recognization is shown in Fig. 4
Complete framework is represent in Fig. 5

Review. 4:
Gabor Kiss et-al, 2017, think about a cross-lingual examination is given with respect to expectation prospects of wretchedness on the base of discourse process.

Our examination was performed on 3 European dialects: German, Hungarian and Italian. Those acoustic choices were assigned, as information vector of the indicator, that relate with the seriousness of sorrow in comparable dialect independent way. Numerous mono and cross-lingual trials were directed. The technique is even fit for foreseeing the seriousness of despondency inside the instance of a dialect not utilized all through the training of the model. The tests plainly demonstrate that trilingual sadness acknowledgment is frequently accomplished, and it should be potential to develop a programmed symptomatic device for analyst work wretchedness, or for understanding viewing, in an exceedingly cross-lingual way.
Fig.6 shows the table of collected dataset. And the result is tabularize in table 1.
 III. CONCLUSION
III. CONCLUSION
Speech signal processing is an active research area in the field of digital signal processing. Speech signal processing was come into the picture in 70’s. Here in this paper we are reviewing the last four years work in the field of speech signal processing. We have reviewed the four papers of speech signal processing and all these papers published from 2017 to 2018. Three papers are published in 2018 and one paper was published in 2017. We found that all four researchers has used the machine learning techniques for the improvement in speech and language recognisation. So we can say that image recognisation is an important tool in the field of speech and text processing.
REFERENCES
- Raczynski, “Speech processing algorithm for isolated words recognition,” 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinoujście, 2018, pp. 27-31.
- Z. Muhammad, M. Nasrun, C. Setianingsih and M. A. Murti, “Speech recognition for English to Indonesian translator using hidden Markov model,” 2018 International Conference on Signals and Systems (ICSigSys), Bali, 2018, pp. 255-260.
- Upadhyaya, S. K. Mittal, Y. V. Varshney, O. Farooq and M. R. Abidi, “Speaker adaptive model for Hindi speech using Kaldi speech recognition toolkit,” 2017 International Conference on Multimedia, Signal Processing and Communication Technologies (IMPACT), Aligarh, 2017, pp. 222-226.
- Kiss and K. Vicsi, “Investigation of cross-lingual depression prediction possibilities based on speech processing,” 2017 8th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Debrecen, 2017, pp. 000097-000102.
- K. Gowda, V. Nimbalker, R. Lavanya, S. Lalitha and S. Tripathi, “Affective computing using speech processing for call centre applications,” 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, 2017, pp. 766-771.
- R. L. Daalache, D. Addou and M. Boudraa, “An efficient distributed speech processing in noisy mobile communications,” 2017 International Conference on Wireless Technologies, Embedded and Intelligent Systems (WITS), Fez, 2017, pp. 1-4.
